Happy pi approximation day 2013
The fraction 22/7 has been known since antiquity as a simple rational approximation of π. The fraction decimal expansion is 3.(142857); since π is about 3.141592653589793, the approximation has three correct digits. Of course nowadays we can compute much better approximations with computers, and billions of digits are known: http://en.wikipedia.org/wiki/Approximations_of_π is a nice review also explaining some efficient computation methods. For example if you want to obtain a lot of π digits in a short time you may like the series by Ramanujan, yielding very good approximations even with a small number of terms; but that’s not the point now.
July 22, written as 22/7 in Europe, has been chosen as π approximation day (http://piapproximationday.com/): people all over the world celebrate it by writing computer programs1 to approximate π, for fun and to educate the public.
My entry for this year follows the same idea I used in 2011, but now I’ve seized the occasion to rewrite the thing in Forth (http://en.wikipedia.org/wiki/Forth_(programming_language)) with simplifications and optimizations. The resulting program I got was so surprisingly lean and simple that it could even serve as a first introduction to Forth. So, I said to myself, why not: I’ll talk a little about this beautiful and neglected language.
The idea
As one definition of π is the area of the unit disk, one way of approximating π is by estimating the area; here, since it’s easier to compute, I will actually estimate the area of a fourth of the disk, and then multiply it by 4 at the end.
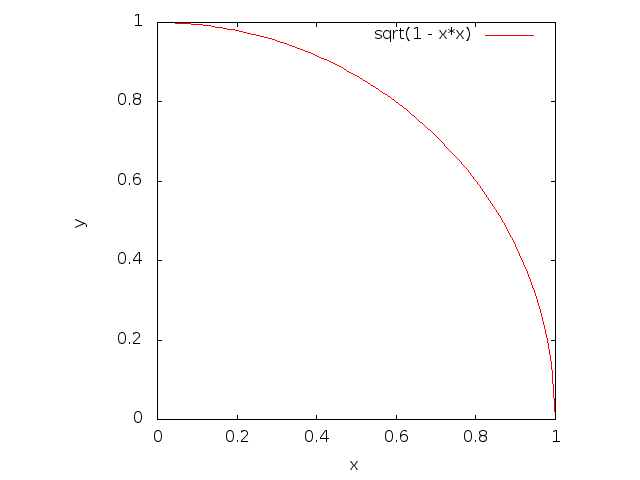
Let’s restrict our attention to the unit square in the first quadrant with a vertex in the origin and two sides lying on the axes: we’re only interested in values with both coordinates lying in [0, 1).
The red curve above is a circular arc: it’s the unit circle centered in the origin, cropped to our square. We can thus say that the red curve is the set of all points <x, y> in the square such that sqrt(x² + y²) = 1. And the area below the red curve, which is what we really care about, is the set of points <x, y> in the square such that sqrt(x² + y²) < 1.
We’ll use a Monte Carlo algorithm (https://en.wikipedia.org/wiki/Monte_Carlo_algorithm): the idea is to pick random points <x, y> in the square, counting how many happen to fall below the curve. Since the square has unit area, the ratio of the number of the points below the curve to the number of all points will yield an approximation of a quarter of π.
Real hackers don’t need floating-point numbers
We don’t really need to work with floating point numbers or indeed with any kind of rationals between 0 and 1: instead we can do everything with naturals, scaling our real segment [0, 1) to a wider segment between 0 and some n, and then taking only its natural elements. So, let’s pick a largish2 natural n and have n be the radius of a larger disk, now working in a square with side n. If our random points have natural coordinates in [0, n) rather than real coordinates in [0, 1), there’s no big change: we just have to remember that the quarter disk is now the set of points <x, y> such that sqrt(x² + y²) < n.
But why bother with square roots at all? As both sides of the inequality are non-negative we can safely square them both, obtaining x² + y² < n².
This inequality is the heart of our algorithm: it’s the property we have to check for each random point to determine if it falls below or above the curve. Written in the form above, with natural numbers only and no square roots, it becomes quite fast to compute; even more so if you also notice that n² is constant.
Algorithm
We generate sampleno random points <x, y> with natural coordinates in [0, n), counting for how many we have that x² + y² < n². This count times four divided by sampleno yields our rational approximation of π.
A Forth crash course
Forth is a simple but powerful programming language, which runs well also on extremely small machines. Its father Chuck Moore, who developed the language in the late Sixties to control telescopes, is now implementing Forth variants at the hardware level, on fast and energy-efficient embedded processors.
Forth programs are simply sequences of numbers and words, a word being a zero-argument zero-result procedure operating on a fixed set of global stacks. You will only need to think of one stack for the π problem, and we’ll simply call it “the stack”.
There are no expressions in Forth: a number represents for all
practical effects an imperative statement; for example ‘43’ means
“push 43 on the stack”. ‘+’ is a predefined word which
consumes the two topmost elements from the stack, replacing them with
their sum. The way of computing the sum of one and two is pushing 1,
then pushing 2, and finally using the word ‘+’. The
phrase is simply written by “concatenation”: ‘1 2 +’.
Since the operands must be on the stack before we can perform an
operation, notation tends to be postfix. When it makes a
difference, arithmetic words popping two arguments from the stack take
the topmost element as their second parameter, and the element
below it as their first; for example the phrase ‘10 3 -’
leaves 7 on the stack (push 10, push 3 over it,
replace both with below-the-top minus top). Of course all the needed
arithmetic operations are available as predefined words.
Stacks are written horizontally in comments, with the top on the right. For example evaluating the phrase ‘10 1 2 + +’ starting from an empty stack, we get the following sequence of stack configurations: ‘’ ⇒ ‘10’ ⇒ ‘10 1’ ⇒ ‘10 1 2’ ⇒ ‘10 3’ ⇒ ‘13’. In comments you typically use metavariables, English or arithmetic expressions to represent elements.
There is a conventional notation for “stack effects”, to be used in comments for showing what a word does to the top few elements of the stack: you write the input stack on the left, two dashes, and then the output stack. Equal metavariables represent equal values.
A wealth of predefined words is available to “juggle” elements on the
stack: for example ‘swap’ swaps the two topmost elements of the
stack. Executing ‘10 20 swap’ with an empty stack yields the
stack ‘20 10’, with 10 on top. So the stack effect of
‘swap’ can be written in a comment as ‘a b -- b a’.
The predefined word ‘dup’ pushes a copy of the top element on the
stack; its stack effect is ‘a -- a a’.
A Forth program will start by using predefined words to define new words; in the end these words will be used to compute something. Factoring is central, and word definitions tend to be very short in well-written programs.
If you want to define a new Forth word, you need the two predefined words ‘:’ and ‘;’. ‘:’ eats the next word in the program, to be used as the name of the new word, then switches to compile state and eats all the words and numbers it finds in the program, appending them to the definition of your new word, until it finds ‘;’, at which point it exits compile state. From that point on your new word is available.
For example, here’s how to define a word ‘average’, computing the
average of two numbers (first replace the two topmost elements
with their sum, then push 2 on top, and finally replace the two new topmost
elements with their quotient); its stack effect can be written as
‘a b -- c’ or, more explicitly, as ‘a b -- [a+b]/2’.
: average + 2 / ;
After the definition, using the word ‘average’ has the same
effect as repeating its body, which is to say the phrase ‘+ 2 /’:
for example ‘10 20 average’ has the effect of pushing 15 on the stack,
exactly like ‘10 20 + 2 /’.
Notice by the way that there’s no need to name parameters.
It’s conventional to add a stack effect comment to your word
definitions, right after the word name. You can enter and exit a
comment using the predefined words ‘(’ and ‘)’, which work
much like ‘:’ and ‘;’ by temporarily switching to a state in
which words and numbers from the programs are eaten — and
ignored, in this case. Notice that you need whitespace around
words, including ‘:’, ‘;’, ‘(’ and ‘)’. With a
stack-effect comment our definition of average becomes:
: average ( a b -- [a+b]/2 )
+ 2 / ;
For completeness, here’s how to make literal strings: you need
the predefined word ‘s"’ which eats characters from the
program up to the character ‘"’, adding them to the string it’s
building; it then pushes the string on the stack, in some form you
aren’t really interested in. So, to push the three-character string
“abc”, you need the Forth phrase ‘s" abc"’. Mind the
space: ‘s"’ is a word, so it must be delimited.
Predefined control words: conditional and loop
At this point you only need to know about a couple control words. ‘if’ pops the top of the stack: if it’s nonzero it goes on and executes the numbers and words that follow, up to the corresponding ‘endif’; otherwise, it simply jumps past the corresponding ‘endif’. You don’t need to know about ‘else’ here, and avoiding it yields simpler programs anyway.
In the next example, notice that I’ve added a stack comment in the body as well, just to make it clear what’s on the top of the stack at that point. It may actually be useful, in more complicated cases.
: foo1 ( -- 57 3 )
1 if 57 3 endif ;
: foo2 ( -- )
1 1 - ( 0 ) if 57 3 endif ;
The loop word we’ll use here is ‘u+do’, useful for simple counted loops with naturals, counting up: ‘u+do’ consumes two elements from the stack: the top one is the initial index, the one below it is the final index. ‘u+do’ executes all the numbers and words that follow up to the corresponding word ‘loop’, looping until the index becomes greater than or equal to the final index (not included).
Using the predefined words ‘i’, which pushes the innermost loop counter, and ‘.’, which consumes the top element from the stack and prints it, we can write:
: foo3 ( -- )
10 0 u+do i . loop ;
Executing ‘foo3’ prints 0 1 2 3 4 5 6 7 8 9.
Approximating π with Forth
This implementation works with GForth (http://www.gnu.org/software/gforth), the Forth system from the GNU Project.
We’ll go to the trouble of using the random number generator included
in GForth, even if its implementation is exactly four lines long. In
order to include a Forth source file to be evaluated you need to use the
predefined word included, which consumes a string from the stack:
s" random.fs" included
Now let’s define some constants: our n, and the number of samples. One way is simply defining them as words which push numbers on the stack, with stack effect ‘-- a’:
: sampleno
10000000 ;
: n
10000 ;
Squaring a number is easy:
: squared ( a -- a² )
dup * ;
Computing a random coordinate is easy as well: you just need ‘random’, which consumes a number m from the stack and pushes a pseudo-random result in [0, m):
: coordinate ( -- a )
n random ;
‘below’ implements the test we described above: given two random coordinates, consumed off the stack, it pushes a flag: nonzero if the point is below the curve, zero otherwise. This word definition needs surprisingly little juggling, which usually means that the code is well-factored. ‘below’ first squares the element on top, which happens to be y; then it swaps y² with x, and squares x. There’s no need to swap again since ‘+’ is commutative, so y² + x² is just as good as x² + y². After the sum we can push n and square it; on the stack we have ‘y²+x² n²’, as shown in the stack comment, and we get the result by checking if the former is smaller than the latter, with ‘<’:
: below ( x y -- f )
squared swap squared + n squared ( y²+x² n² ) < ;
How do we count the number of samples below the curve? My idea is to keep a number on the top of the stack, and test one sample: if the sample is below the curve then we increment the number, otherwise we leave it alone. This “flows” very nicely on the stack, again without need for juggling. The predefined word ‘1+’ increments the top of the stack: it’s just a faster way of executing the phrase ‘1 +’.
: 1sample ( u -- v )
coordinate coordinate below if 1+ endif ;
Cool. Now we just have to make the counter by pushing zero, and call ‘1sample’ a certain number of times to get our count. This number of times is taken off the stack. Notice that the two loop indices are consumed by ‘u+do’, so that at loop entry we have the counter on the top of the stack, as we need when using ‘1sample’. We don’t even need the loop index:
: countbelow ( u -- v )
0 swap 0 u+do 1sample loop ;
The main word ‘go’ pushes the denominator and numerator on the
stack (numerator on top). Notice how we use ‘dup’ to push a copy
of sampleno: the top one will be consumed by countbelow, the
other will serve as the denominator in the end. The final
multiplication by 4 affects the top, which is the numerator.
: go ( -- denominator numerator )
sampleno dup countbelow 4 * ;
At this point we can call ‘go’, and print the result: it’s good to have the numerator on top, so that we can print it first with ‘.’, consuming it; then we call again ‘.’ for the denominator, print a new line with ‘cr’, and exit with ‘bye’:
go . . cr bye
That’s it. Here’s the complete program again, written in a natural style, just to show you how short it is:
s" random.fs" included
: sampleno
10000000 ;
: n
10000 ;
: squared ( a -- a² )
dup * ;
: coordinate ( -- a )
n random ;
: below ( x y -- f )
squared swap squared + n squared ( y²+x² n² ) < ;
: 1sample ( u -- v )
coordinate coordinate below if 1+ endif ;
: countbelow ( u -- v )
0 swap 0 u+do 1sample loop ;
: go ( -- denominator numerator )
sampleno dup countbelow 4 * ;
go . . cr bye
It works, printing ‘31422528 10000000’.
Performance
There are essentially two easy optimizations to perform:
- The first one is less interesting: we can use the predefined word ‘constant’ to define a constant instead of an ordinary ‘:’-definition. efficiency is the only difference, and the stack effects don’t change;
- the second optimization is more interesting. In the definition of ‘below’ we have the phrase ‘n squared’: every time it’s executed we have to pay the price of squaring, when we could pre-compute the result once and for all. It’s much better to replace ‘n squared’ with a new word ‘nsquared’, to be defined as a constant — using a ‘:’-definition wouldn’t avoid the repeated squaring.
These two optimizations yield a reasonable speedup. The final Forth program becomes:
s" random.fs" included
10000000 constant sampleno
10000 constant n
: squared
dup * ;
n squared constant nsquared
: coordinate
n random ;
: below ( x y -- b )
squared swap squared + nsquared ( y²+x² n² ) < ;
: 1sample ( u -- v )
coordinate coordinate below if 1+ endif ;
: countbelow ( u -- v )
0 swap 0 u+do 1sample loop ;
: go ( -- denominator numerator )
sampleno dup countbelow 4 * ;
go . . cr bye
Let’s compare the Forth program with a similar program written in C using the same algorithm, and compiled with aggressive optimizations:
#include <stdio.h>
#include <stdlib.h>
#define SAMPLE_NO 10000000
#define N 10000
int squared(int n){
return n * n;
}
int coordinate(void){
return rand() % N;
}
int below(int x, int y){
return (squared(x) + squared(y)) < squared(N);
}
int main(void){
int i, count = 0;
for(i = 0; i < SAMPLE_NO; i ++)
if(below(coordinate(), coordinate()))
count ++;
printf("%i %i\n", 4 * count, SAMPLE_NO);
return EXIT_SUCCESS;
}
I used the gforth-fast interpreter from GForth git (latest
version as of 2013-07-18) and GCC 4.8.1 with the option -Ofast,
on a recent amd64 machine. Timings were consistent between runs.
time -p ~/projects-by-others/gforth-git/gforth-fast ./pi-approximation-day-2013.fs ⊣ 31422528 10000000 ⊣ real 0.87 ⊣ user 0.87 ⊣ sys 0.00 time -p ./pi-approximation-day-2013-c ⊣ 31423664 10000000 ⊣ real 0.26 ⊣ user 0.26 ⊣ sys 0.00
The C version, compiled to native assembly by an extremely complex optimizing compiler, is only 3.35 times faster than GForth’s threaded code (https://en.wikipedia.org/wiki/Threaded_code). I find the performance of the Forth version quite impressive.
Closing
I hope that you had fun with π approximations, and that I made you curious about Forth.
I’ve only shown the most basic features of Forth, in particular neglecting meta-programming, a strong point of the language. I’m far from a Forth master myself and I won’t vouch here for its suitability to any problem in particular; however I do see its beauty, and if nothing else I can witness how writing good Forth is a deeply satisfying intellectual exercise.
The GForth manual contains a real tutorial introduction, very well-written and starting from scratch; I highly recommend it. An HTML version is available at http://www.complang.tuwien.ac.at/forth/gforth/Docs-html/, but if you’re serious about programming you should use Info from Emacs instead; the text is identical, but navigation and searching will be much more convenient in Info.
I release the Forth and C source code in this article into the public domain, up to the extent permitted by law.
— Luca Saiu, 2013-07-21 12:34 (last update: 2014-07-21 21:14)
|
|
Tags: forth, gnu, hacking, pi, tutorial |
| Next post | Previous post |
You might want to go to
the
main blog index
(![]() feeds for every post:
Atom 1.0,
RSS 2.0)
or to my web site
feeds for every post:
Atom 1.0,
RSS 2.0)
or to my web site
https://ageinghacker.net.
![[my photo]](/static/my-photo.jpg)
Luca Saiu |
The opinions I express here are my own and do not
necessarily reflect the beliefs or policies of my
employer or for that matter of anyone else. In case you
felt that the public statement of my thoughts threatened
your warm sense of security and your emotional stability
feel free to leave at any time.
You might be interested in my web site
|
Copyright © 2009, 2011-2014, 2017, 2018, 2021-2024 Luca Saiu
Verbatim copying and redistribution of this entire page are permitted
in any medium without royalties, provided this notice is preserved.
This page was generated by trivialblog.
trivialblog is
free software,
available under the
GNU GPL.
Tag icon copyright information is available
in this file.
Footnotes
(1)
How beautiful the world would be.
(2)
Please don’t cringe, mathematicians. All right, if you want a better approximation of π and your machine is 64-bit then you should use a value larger than 10000, as long as n² doesn’t overflow. 10⁸ is small enough to fit in 32-bit registers, and in this introduction we don’t particularly care about the quality of the final result anyway. There are much better ways of approximating π: the purpose of this post is to cause an ooh moment.